Derivative-Enhanced Gaussian Process (DEGP)#
Overview#
The Derivative-Enhanced Gaussian Process (DEGP) extends standard Gaussian Process (GP) regression by incorporating derivative information at training points. This enables the model to:
Capture local nonlinear behavior more accurately
Improve predictions in regions where function samples are sparse
Refine uncertainty estimates and predictive gradients using higher-order information
This tutorial demonstrates DEGP on 1D and 2D functions, first using first-order derivatives only, and then including second-order derivatives for improved curvature representation.
The examples also illustrate how DEGP predictions can be validated at training points and visualized over a range of inputs.
—
Example 1: 1D First-Order Derivatives Only#
Overview#
Learn a 1D function \(f(x) = \sin(x)\) using both the function values and its first derivative \(f'(x) = \cos(x)\). Incorporating derivatives allows the GP to respect the slope of the function, leading to more accurate interpolation.
—
Step 1: Import required packages#
import numpy as np
from jetgp.full_degp.degp import degp
import matplotlib.pyplot as plt
print("Modules imported successfully.")
Modules imported successfully.
Explanation:
We import numpy for numerical operations, matplotlib.pyplot for visualization, and the DEGP class from the full_degp package.
—
Step 2: Define training data#
X_train = np.array([[0.0], [0.5], [1.0]])
y_func = np.sin(X_train)
y_deriv1 = np.cos(X_train)
y_train = [y_func, y_deriv1]
print("X_train:", X_train)
print("y_train:", y_train)
X_train: [[0. ]
[0.5]
[1. ]]
y_train: [array([[0. ],
[0.47942554],
[0.84147098]]), array([[1. ],
[0.87758256],
[0.54030231]])]
Explanation:
Here, we define three training points and compute their function values and first derivatives. y_train is a list containing both values and derivatives, which the DEGP model will use for training.
—
Step 3: Define derivative indices and locations#
der_indices = [[[[1, 1]]]]
# derivative_locations must be provided - one entry per derivative
derivative_locations = []
for i in range(len(der_indices)):
for j in range(len(der_indices[i])):
derivative_locations.append([k for k in range(len(X_train))])
print("der_indices:", der_indices)
print("derivative_locations:", derivative_locations)
der_indices: [[[[1, 1]]]]
derivative_locations: [[0, 1, 2]]
Explanation:
der_indices tells the DEGP model which derivatives to include. In 1D, the first order derivative is labeled as [[1,1]]. derivative_locations specifies which training points have each derivative—here, all points have the first derivative.
—
Step 4: Initialize DEGP model#
model = degp(X_train, y_train, n_order=1, n_bases=1,
der_indices=der_indices,
derivative_locations=derivative_locations,
normalize=True,
kernel="SE", kernel_type="anisotropic")
print("DEGP model initialized.")
DEGP model initialized.
Explanation:
- n_order=1 specifies first-order derivatives
- kernel="SE" uses a Squared Exponential kernel
- kernel_type="anisotropic" allows the model to learn separate length scales for each dimension
- normalize=True ensures that both function values and derivatives are scaled for numerical stability
—
Step 5: Optimize hyperparameters#
params = model.optimize_hyperparameters(
optimizer='pso',
pop_size = 100,
n_generations = 15,
local_opt_every = 15,
debug = False
)
print("Optimized hyperparameters:", params)
Stopping: maximum iterations reached --> 15
Optimized hyperparameters: [-0.79592036 0.75114571 -8.35496602]
Explanation: Hyperparameters of the kernel (length scale, variance, noise, etc.) are optimized by maximizing the marginal log likelihood. Particle Swarm Optimization (PSO) is used here for robustness.
—
Step 6: Validate predictions at training points#
y_train_pred = model.predict(X_train, params, calc_cov=False, return_deriv=True)
# Output shape is [n_derivatives + 1, n_points]
# Row 0: function values, Row 1: first derivative
y_func_pred = y_train_pred[0, :]
y_deriv_pred = y_train_pred[1, :]
abs_error_func = np.abs(y_func_pred.flatten() - y_func.flatten())
abs_error_deriv = np.abs(y_deriv_pred.flatten() - y_deriv1.flatten())
print("Absolute error (function) at training points:", abs_error_func)
print("Absolute error (derivative) at training points:", abs_error_deriv)
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]]]
Absolute error (function) at training points: [8.64208705e-12 3.13638004e-14 1.59205982e-12]
Absolute error (derivative) at training points: [1.26565425e-14 9.01723141e-13 1.78046466e-12]
Explanation:
We first check predictions at training points to ensure that the DEGP model exactly interpolates function values and derivatives, as expected for noiseless training data. The output has shape [n_derivatives + 1, n_points] where row 0 contains function predictions and subsequent rows contain derivative predictions.
—
Step 7: Visualize predictions#
X_test = np.linspace(0, 1, 100).reshape(-1, 1)
y_test_pred = model.predict(X_test, params, calc_cov=False, return_deriv=True)
# Row 0: function, Row 1: first derivative
y_func_test = y_test_pred[0, :]
y_deriv_test = y_test_pred[1, :]
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
plt.plot(X_test, np.sin(X_test), 'k--', label='True f(x)')
plt.plot(X_test, y_func_test, 'r-', label='GP prediction')
plt.scatter(X_train, y_func, c='b', s=50, label='Training points')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Function and GP Prediction')
plt.legend()
plt.subplot(1,2,2)
plt.plot(X_test, np.cos(X_test), 'k--', label="True f'(x)")
plt.plot(X_test, y_deriv_test, 'r-', label='GP derivative prediction')
plt.scatter(X_train, y_deriv1, c='b', s=50, label='Training points')
plt.xlabel('x')
plt.ylabel("f'(x)")
plt.title('Derivative and GP Prediction')
plt.legend()
plt.tight_layout()
plt.show()
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]]]
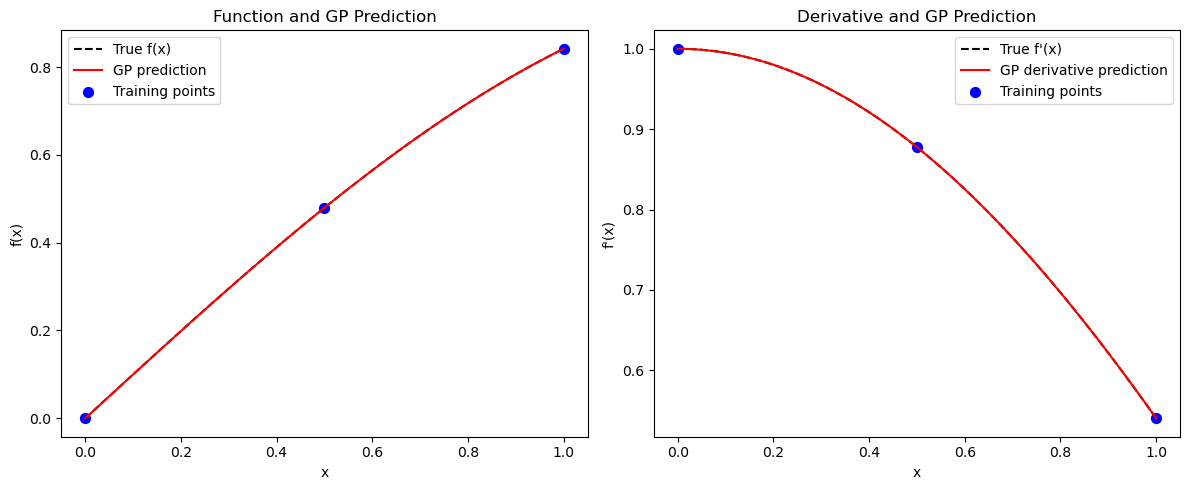
Explanation: The plots compare DEGP predictions with the true function and derivatives.
—
Summary#
This example demonstrates first-order DEGP on a 1D function. By incorporating derivative information at training points, the GP achieves:
Exact interpolation of both function values and slopes at training locations
Improved accuracy between training points
Better extrapolation behavior near boundaries
—
Example 2: 1D First- and Second-Order Derivatives#
Overview#
Improve the GP model by incorporating second-order derivatives. This gives the GP information about curvature, enhancing interpolation and derivative predictions.
—
Step 1: Define training data#
X_train = np.array([[0.0], [0.5], [1.0]])
y_func = np.sin(X_train)
y_deriv1 = np.cos(X_train)
y_deriv2 = -np.sin(X_train)
y_train = [y_func, y_deriv1, y_deriv2]
print("X_train:", X_train)
print("y_train:", y_train)
X_train: [[0. ]
[0.5]
[1. ]]
y_train: [array([[0. ],
[0.47942554],
[0.84147098]]), array([[1. ],
[0.87758256],
[0.54030231]]), array([[-0. ],
[-0.47942554],
[-0.84147098]])]
Explanation: The second derivative is included in the training data. DEGP can now enforce both slope and curvature.
—
Step 2: Define derivative indices and locations#
der_indices = [[[[1, 1]], [[1, 2]]]]
# All derivatives at all training points
derivative_locations = []
for i in range(len(der_indices)):
for j in range(len(der_indices[i])):
derivative_locations.append([k for k in range(len(X_train))])
print("der_indices:", der_indices)
print("derivative_locations:", derivative_locations)
der_indices: [[[[1, 1]], [[1, 2]]]]
derivative_locations: [[0, 1, 2], [0, 1, 2]]
Explanation:
The first order derivative is labeled [[1,1]] and the second order derivative [[1,2]]. derivative_locations specifies that both derivatives are available at all training points.
—
Step 3: Initialize DEGP model for second-order derivatives#
model = degp(X_train, y_train, n_order=2, n_bases=1,
der_indices=der_indices,
derivative_locations=derivative_locations,
normalize=True,
kernel="SE", kernel_type="anisotropic")
print("DEGP model (2nd order) initialized.")
DEGP model (2nd order) initialized.
Explanation:
Setting n_order=2 instructs the model to incorporate both first- and second-order derivatives.
—
Step 4: Optimize hyperparameters#
params = model.optimize_hyperparameters(
optimizer='pso',
pop_size = 100,
n_generations = 15,
local_opt_every = 15,
debug = True
)
print("Optimized hyperparameters:", params)
New best for swarm at iteration 1: [-0.60812005 0.34549871 -6.32207447] -34.006062561208275
Best after iteration 1: [-0.60812005 0.34549871 -6.32207447] -34.006062561208275
Best after iteration 2: [-0.60812005 0.34549871 -6.32207447] -34.006062561208275
New best for swarm at iteration 3: [-0.86011993 1.37439028 -7.12325797] -36.28910006317677
Best after iteration 3: [-0.86011993 1.37439028 -7.12325797] -36.28910006317677
New best for swarm at iteration 4: [-0.77097232 0.61780118 -6.30445074] -39.14169411769196
Best after iteration 4: [-0.77097232 0.61780118 -6.30445074] -39.14169411769196
New best for swarm at iteration 5: [-0.86584625 1.06557634 -8.50315447] -40.858224603571486
New best for swarm at iteration 5: [-0.77207861 0.63088356 -7.54244312] -42.00212158203552
Best after iteration 5: [-0.77207861 0.63088356 -7.54244312] -42.00212158203552
Best after iteration 6: [-0.77207861 0.63088356 -7.54244312] -42.00212158203552
Best after iteration 7: [-0.77207861 0.63088356 -7.54244312] -42.00212158203552
New best for swarm at iteration 8: [-0.79554057 0.65481256 -7.92234433] -42.127663086996684
Best after iteration 8: [-0.79554057 0.65481256 -7.92234433] -42.127663086996684
New best for swarm at iteration 9: [-0.7950314 0.71319527 -7.52673956] -43.308113707113925
New best for swarm at iteration 9: [-0.79121866 0.67783742 -7.50496889] -43.53304629142166
Best after iteration 9: [-0.79121866 0.67783742 -7.50496889] -43.53304629142166
Best after iteration 10: [-0.79121866 0.67783742 -7.50496889] -43.53304629142166
Best after iteration 11: [-0.79121866 0.67783742 -7.50496889] -43.53304629142166
New best for swarm at iteration 12: [-0.79496483 0.65926043 -7.55058814] -44.18980550636026
Best after iteration 12: [-0.79496483 0.65926043 -7.55058814] -44.18980550636026
Best after iteration 13: [-0.79496483 0.65926043 -7.55058814] -44.18980550636026
Best after iteration 14: [-0.79496483 0.65926043 -7.55058814] -44.18980550636026
Best after iteration 15: [-0.79496483 0.65926043 -7.55058814] -44.18980550636026
Stopping: maximum iterations reached --> 15
Optimized hyperparameters: [-0.79496483 0.65926043 -7.55058814]
Explanation: Hyperparameters of the kernel are optimized by maximizing the marginal log likelihood. Particle Swarm Optimization (PSO) is used here for robustness.
—
Step 5: Validate predictions at training points#
y_train_pred = model.predict(X_train, params, calc_cov=False, return_deriv=True)
# Output shape is [n_derivatives + 1, n_points]
# Row 0: function, Row 1: 1st derivative, Row 2: 2nd derivative
y_func_pred = y_train_pred[0, :]
y_deriv1_pred = y_train_pred[1, :]
y_deriv2_pred = y_train_pred[2, :]
abs_error_func = np.abs(y_func_pred.flatten() - y_func.flatten())
abs_error_deriv1 = np.abs(y_deriv1_pred.flatten() - y_deriv1.flatten())
abs_error_deriv2 = np.abs(y_deriv2_pred.flatten() - y_deriv2.flatten())
print("Absolute error (function) at training points:", abs_error_func)
print("Absolute error (1st derivative) at training points:", abs_error_deriv1)
print("Absolute error (2nd derivative) at training points:", abs_error_deriv2)
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[1, 2]]]
Warning: Cholesky decomposition failed via scipy, using standard np solve instead.
Absolute error (function) at training points: [2.39336595e-09 1.44918683e-09 5.23176102e-09]
Absolute error (1st derivative) at training points: [5.27460076e-10 9.93388150e-10 1.51192014e-09]
Absolute error (2nd derivative) at training points: [1.27135123e-09 2.15520962e-09 2.29917752e-10]
Explanation: With second derivatives included, DEGP predictions should match both slopes and curvature at training points.
—
Step 6: Visualize predictions#
X_test = np.linspace(0, 1, 100).reshape(-1, 1)
y_test_pred = model.predict(X_test, params, calc_cov=False, return_deriv=True)
# Row 0: function, Row 1: 1st derivative, Row 2: 2nd derivative
y_func_test = y_test_pred[0, :]
y_deriv1_test = y_test_pred[1, :]
y_deriv2_test = y_test_pred[2, :]
plt.figure(figsize=(18,5))
plt.subplot(1,3,1)
plt.plot(X_test, np.sin(X_test), 'k--', label='True f(x)')
plt.plot(X_test, y_func_test, 'r-', label='GP prediction')
plt.scatter(X_train, y_func, c='b', s=50, label='Training points')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Function')
plt.legend()
plt.subplot(1,3,2)
plt.plot(X_test, np.cos(X_test), 'k--', label="True f'(x)")
plt.plot(X_test, y_deriv1_test, 'r-', label='GP derivative prediction')
plt.scatter(X_train, y_deriv1, c='b', s=50, label='Training points')
plt.xlabel('x')
plt.ylabel("f'(x)")
plt.title('1st Derivative')
plt.legend()
plt.subplot(1,3,3)
plt.plot(X_test, -np.sin(X_test), 'k--', label="True f''(x)")
plt.plot(X_test, y_deriv2_test, 'r-', label='GP 2nd derivative prediction')
plt.scatter(X_train, y_deriv2, c='b', s=50, label='Training points')
plt.xlabel('x')
plt.ylabel("f''(x)")
plt.title('2nd Derivative')
plt.legend()
plt.tight_layout()
plt.show()
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[1, 2]]]
Warning: Cholesky decomposition failed via scipy, using standard np solve instead.
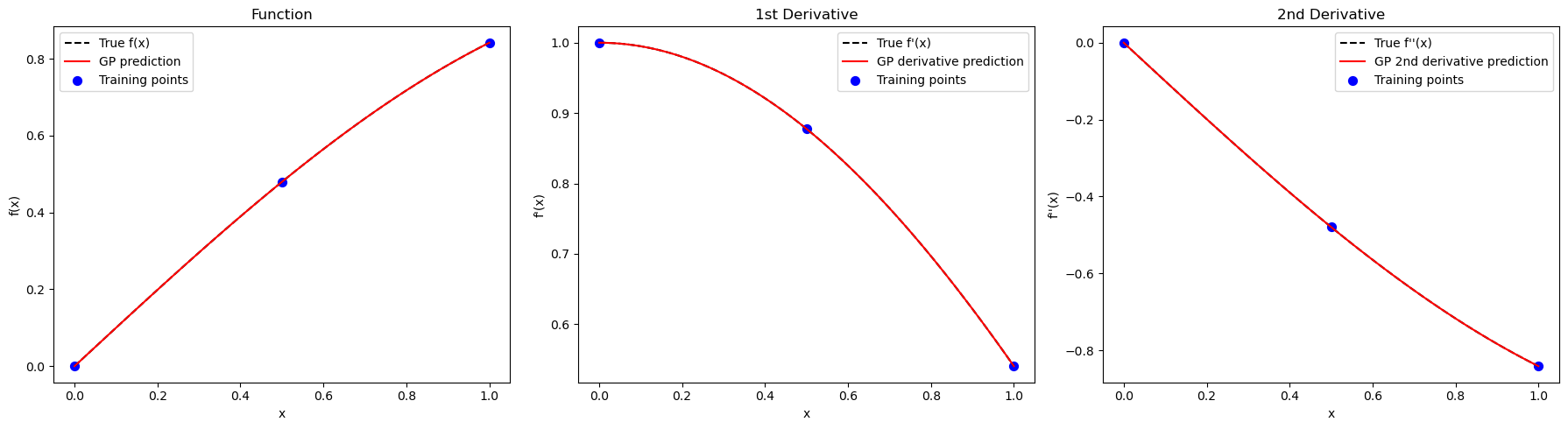
Explanation: The three-panel plot shows function, first derivative, and second derivative predictions. Including higher-order derivatives improves the model’s ability to interpolate curvature between points.
—
Summary#
This example demonstrates second-order DEGP on a 1D function. By incorporating both first and second derivatives:
The GP captures local curvature information
Predictions are more accurate in regions with high curvature
Derivative predictions are smoother and more reliable
—
Example 3: 2D First-Order Derivatives#
Overview#
Learn a 2D function \(f(x,y) = \sin(x)\cos(y)\) using function values and first derivatives with respect to \(x\) and \(y\).
—
Step 1: Import required packages#
import numpy as np
from jetgp.full_degp.degp import degp
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
print("Modules imported successfully for 2D example.")
Modules imported successfully for 2D example.
Explanation: Additional imports for 3D visualization are included.
—
Step 2: Define training data#
X1 = np.array([0.0, 0.5, 1.0])
X2 = np.array([0.0, 0.5, 1.0])
X1_grid, X2_grid = np.meshgrid(X1, X2)
X_train = np.column_stack([X1_grid.flatten(), X2_grid.flatten()])
y_func = np.sin(X_train[:,0]) * np.cos(X_train[:,1])
y_deriv_x = np.cos(X_train[:,0]) * np.cos(X_train[:,1])
y_deriv_y = -np.sin(X_train[:,0]) * np.sin(X_train[:,1])
y_train = [y_func.reshape(-1,1), y_deriv_x.reshape(-1,1), y_deriv_y.reshape(-1,1)]
print("X_train shape:", X_train.shape)
print("y_train shapes:", [v.shape for v in y_train])
X_train shape: (9, 2)
y_train shapes: [(9, 1), (9, 1), (9, 1)]
Explanation: We define a 3×3 2D grid. Function values and first derivatives in both dimensions are included, allowing DEGP to learn the local slopes along each axis.
—
Step 3: Define derivative indices and locations#
der_indices = [[[[1, 1]], [[2, 1]]]]
# All derivatives at all training points
derivative_locations = []
for i in range(len(der_indices)):
for j in range(len(der_indices[i])):
derivative_locations.append([k for k in range(len(X_train))])
print("der_indices:", der_indices)
print("derivative_locations:", derivative_locations)
der_indices: [[[[1, 1]], [[2, 1]]]]
derivative_locations: [[0, 1, 2, 3, 4, 5, 6, 7, 8], [0, 1, 2, 3, 4, 5, 6, 7, 8]]
Explanation:
The derivative indices specify first derivatives with respect to \(x\) ([[1,1]]) and \(y\) ([[2,1]]). derivative_locations indicates both partial derivatives are available at all 9 training points.
—
Step 4: Initialize DEGP model#
model = degp(X_train, y_train, n_order=1, n_bases=2,
der_indices=der_indices,
derivative_locations=derivative_locations,
normalize=True,
kernel="SE", kernel_type="anisotropic")
print("2D DEGP model initialized.")
2D DEGP model initialized.
Explanation:
Here, (n_bases=2) which specifices the dimensionality of the problem.
—
Step 5: Optimize hyperparameters#
params = model.optimize_hyperparameters(
optimizer='pso',
pop_size = 100,
n_generations = 15,
local_opt_every = 15,
debug = False
)
print("Optimized hyperparameters:", params)
Stopping: maximum iterations reached --> 15
Optimized hyperparameters: [ -0.67306813 -0.7377549 0.68515504 -11.73930474]
Explanation: Hyperparameter optimization for 2D problems may take longer due to increased dimensionality.
—
Step 6: Validate predictions at training points#
y_train_pred = model.predict(X_train, params, calc_cov=False, return_deriv=True)
# Output shape is [n_derivatives + 1, n_points]
# Row 0: function, Row 1: df/dx, Row 2: df/dy
y_func_pred = y_train_pred[0, :]
y_deriv_x_pred = y_train_pred[1, :]
y_deriv_y_pred = y_train_pred[2, :]
print("Predictions at training points (function):", y_func_pred)
print("Predictions at training points (deriv x):", y_deriv_x_pred)
print("Predictions at training points (deriv y):", y_deriv_y_pred)
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[2, 1]]]
Predictions at training points (function): [-3.73273079e-11 4.79425538e-01 8.41470985e-01 3.07638914e-11
4.20735492e-01 7.38460263e-01 1.52025892e-10 2.59034724e-01
4.54648713e-01]
Predictions at training points (deriv x): [1. 0.87758256 0.54030231 0.87758256 0.77015115 0.47415988
0.54030231 0.47415988 0.29192658]
Predictions at training points (deriv y): [-1.52834267e-11 -3.98698087e-12 6.64496811e-12 5.64822289e-12
-2.29848847e-01 -4.03422680e-01 -1.72769171e-11 -4.03422680e-01
-7.08073418e-01]
Explanation: Predictions are split into function values and derivatives for each dimension.
—
Step 7: Compute absolute errors#
abs_error_func = np.abs(y_func_pred.flatten() - y_func)
abs_error_dx = np.abs(y_deriv_x_pred.flatten() - y_deriv_x)
abs_error_dy = np.abs(y_deriv_y_pred.flatten() - y_deriv_y)
print("Absolute error (function) at training points:", abs_error_func)
print("Absolute error (deriv x) at training points:", abs_error_dx)
print("Absolute error (deriv y) at training points:", abs_error_dy)
Absolute error (function) at training points: [3.73273079e-11 1.10396636e-10 2.25108487e-10 3.07638914e-11
8.05978617e-11 1.23871691e-10 1.52025892e-10 3.17317284e-11
5.29657429e-11]
Absolute error (deriv x) at training points: [1.71652692e-11 9.02500297e-13 3.28419514e-11 4.80211426e-11
3.73590048e-12 3.72767373e-11 3.61644048e-11 1.67603709e-11
1.36312073e-11]
Absolute error (deriv y) at training points: [1.52834267e-11 3.98698087e-12 6.64496811e-12 5.64822289e-12
2.31470398e-12 6.94777569e-12 1.72769171e-11 1.79119497e-11
1.23127064e-11]
Explanation: Verification that the model exactly interpolates training data.
—
Step 8: Generate test predictions#
x1_test = np.linspace(0, 1, 50)
x2_test = np.linspace(0, 1, 50)
X1_test, X2_test = np.meshgrid(x1_test, x2_test)
X_test = np.column_stack([X1_test.flatten(), X2_test.flatten()])
y_test_pred = model.predict(X_test, params, calc_cov=False, return_deriv=True)
# Row 0: function, Row 1: df/dx, Row 2: df/dy
y_func_test = y_test_pred[0, :].reshape(50, 50)
y_deriv_x_test = y_test_pred[1, :].reshape(50, 50)
y_deriv_y_test = y_test_pred[2, :].reshape(50, 50)
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[2, 1]]]
Explanation: A dense 50×50 test grid is created for visualization purposes.
—
Step 9: Visualize 2D predictions#
import matplotlib.pyplot as plt
# Compute absolute errors for function and first derivatives
abs_error_func = np.abs(y_func_test - (np.sin(X1_test) * np.cos(X2_test)))
abs_error_dx = np.abs(y_deriv_x_test - (np.cos(X1_test) * np.cos(X2_test)))
abs_error_dy = np.abs(y_deriv_y_test - (-np.sin(X1_test) * np.sin(X2_test)))
# Setup figure
fig, axs = plt.subplots(1, 3, figsize=(18, 5))
# Titles and error arrays
titles = [
r'Absolute Error: $f(x,y)$',
r'Absolute Error: $\partial f / \partial x$',
r'Absolute Error: $\partial f / \partial y$'
]
errors = [abs_error_func, abs_error_dx, abs_error_dy]
cmaps = ['Reds', 'Greens', 'Blues']
# Plot each contour
for ax, err, title, cmap in zip(axs, errors, titles, cmaps):
cs = ax.contourf(X1_test, X2_test, err, levels=50, cmap=cmap)
ax.scatter(X_train[:,0], X_train[:,1], c='k', s=40)
ax.set_title(title, fontsize=14)
ax.set_xlabel('x')
ax.set_ylabel('y')
fig.colorbar(cs, ax=ax)
plt.tight_layout()
plt.show()
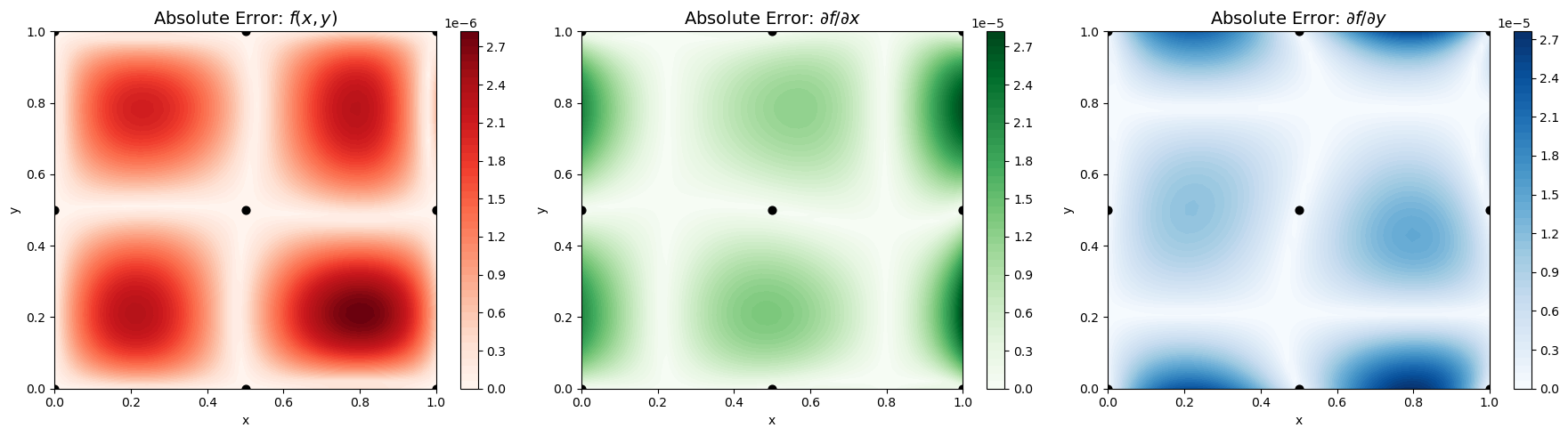
Explanation: The contour plots show absolute errors for the function and its first derivatives. Including derivatives along each dimension allows the GP to capture local slopes, resulting in smoother and more accurate surfaces.
—
Summary#
This example demonstrates 2D first-order DEGP. By incorporating partial derivatives:
The GP learns directional slopes in the 2D space
Predictions are accurate across the entire domain
The model captures local gradient information effectively
—
Example 4: 2D Second-Order (Main) Derivatives#
Overview#
Learn a 2D function \(f(x,y) = \sin(x)\cos(y)\) using function values, first derivatives, and second-order derivatives \(\frac{\partial^2 f}{\partial x^2}\) and \(\frac{\partial^2 f}{\partial y^2}\) (excluding mixed partials).
—
Step 1: Import required packages#
import numpy as np
from jetgp.full_degp.degp import degp
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
print("Modules imported successfully for 2D example with second-order derivatives.")
Modules imported successfully for 2D example with second-order derivatives.
Explanation: Same imports as the previous 2D example.
—
Step 2: Define training data#
X1 = np.array([0.0, 0.5, 1.0])
X2 = np.array([0.0, 0.5, 1.0])
X1_grid, X2_grid = np.meshgrid(X1, X2)
X_train = np.column_stack([X1_grid.flatten(), X2_grid.flatten()])
# True function and derivatives
y_func = np.sin(X_train[:,0]) * np.cos(X_train[:,1])
y_deriv_x = np.cos(X_train[:,0]) * np.cos(X_train[:,1])
y_deriv_y = -np.sin(X_train[:,0]) * np.sin(X_train[:,1])
y_deriv_xx = -np.sin(X_train[:,0]) * np.cos(X_train[:,1])
y_deriv_yy = -np.sin(X_train[:,0]) * np.cos(X_train[:,1])
y_train = [
y_func.reshape(-1,1),
y_deriv_x.reshape(-1,1),
y_deriv_y.reshape(-1,1),
y_deriv_xx.reshape(-1,1),
y_deriv_yy.reshape(-1,1)
]
print("X_train shape:", X_train.shape)
print("y_train shapes:", [v.shape for v in y_train])
X_train shape: (9, 2)
y_train shapes: [(9, 1), (9, 1), (9, 1), (9, 1), (9, 1)]
Explanation: This dataset includes function values, first derivatives, and second-order main derivatives, allowing DEGP to leverage curvature information for improved learning accuracy.
—
Step 3: Define derivative indices and locations#
der_indices = [
[ [[1, 1]], [[2, 1]] ], # first-order derivatives
[ [[1, 2]], [[2, 2]] ] # second-order derivatives
]
# All derivatives at all training points
derivative_locations = []
for i in range(len(der_indices)):
for j in range(len(der_indices[i])):
derivative_locations.append([k for k in range(len(X_train))])
print("der_indices:", der_indices)
print("derivative_locations:", derivative_locations)
der_indices: [[[[1, 1]], [[2, 1]]], [[[1, 2]], [[2, 2]]]]
derivative_locations: [[0, 1, 2, 3, 4, 5, 6, 7, 8], [0, 1, 2, 3, 4, 5, 6, 7, 8], [0, 1, 2, 3, 4, 5, 6, 7, 8], [0, 1, 2, 3, 4, 5, 6, 7, 8]]
Explanation:
The derivative indices specify both first-order and second-order partial derivatives with respect to \(x\) and \(y\). derivative_locations indicates all 4 derivative types are available at all 9 training points.
—
Step 4: Initialize DEGP model#
model = degp(X_train, y_train, n_order=2, n_bases=2,
der_indices=der_indices,
derivative_locations=derivative_locations,
normalize=True,
kernel="SE", kernel_type="anisotropic")
print("2D DEGP model with second-order derivatives initialized.")
2D DEGP model with second-order derivatives initialized.
Explanation:
Setting n_order=2 enables the model to use both first and second-order derivative information.
—
Step 5: Optimize hyperparameters#
params = model.optimize_hyperparameters(
optimizer='pso',
pop_size = 100,
n_generations = 15,
local_opt_every = 15,
debug = False
)
print("Optimized hyperparameters:", params)
Stopping: maximum iterations reached --> 15
Optimized hyperparameters: [ -0.68520552 -0.66361933 0.52920143 -13.18327835]
Explanation: Hyperparameters of the kernel are optimized by maximizing the marginal log likelihood.
—
Step 6: Validate predictions at training points#
y_train_pred = model.predict(X_train, params, calc_cov=False, return_deriv=True)
# Output shape is [n_derivatives + 1, n_points]
# Row 0: function, Row 1: df/dx, Row 2: df/dy, Row 3: d²f/dx², Row 4: d²f/dy²
y_func_pred = y_train_pred[0, :]
y_deriv_x_pred = y_train_pred[1, :]
y_deriv_y_pred = y_train_pred[2, :]
y_deriv_xx_pred = y_train_pred[3, :]
y_deriv_yy_pred = y_train_pred[4, :]
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[2, 1]], [[1, 2]], [[2, 2]]]
Explanation: Predictions are organized by derivative order and type.
—
Step 7: Compute absolute errors#
# First-order errors
abs_error_func = np.abs(y_func_pred.flatten() - y_func)
abs_error_dx = np.abs(y_deriv_x_pred.flatten() - y_deriv_x)
abs_error_dy = np.abs(y_deriv_y_pred.flatten() - y_deriv_y)
# Second-order main derivative errors
abs_error_dxx = np.abs(y_deriv_xx_pred.flatten() - y_deriv_xx)
abs_error_dyy = np.abs(y_deriv_yy_pred.flatten() - y_deriv_yy)
# Print absolute errors
print("Absolute error (function) :", abs_error_func)
print("Absolute error (derivative x) :", abs_error_dx)
print("Absolute error (derivative y) :", abs_error_dy)
print("Absolute error (second x-x) :", abs_error_dxx)
print("Absolute error (second y-y) :", abs_error_dyy)
Absolute error (function) : [2.52768654e-08 1.60906034e-07 1.35368510e-07 1.62180755e-08
7.50793940e-08 1.63332514e-07 6.96886056e-08 1.01456696e-07
1.23133645e-07]
Absolute error (derivative x) : [1.03199227e-09 1.37350364e-09 3.28260918e-08 2.77699750e-08
8.61559712e-10 8.69844474e-10 3.84339893e-09 7.62644808e-09
1.02488575e-08]
Absolute error (derivative y) : [1.17589356e-08 3.62762099e-08 8.88830934e-09 2.66649280e-08
2.57774815e-08 1.99548687e-08 2.78982341e-08 1.12605335e-08
4.43919046e-09]
Absolute error (second x-x) : [1.32362785e-08 4.96790827e-08 3.60800354e-08 7.15397089e-08
4.42814444e-08 3.76778233e-08 5.39412530e-08 3.57222632e-08
2.48760330e-08]
Absolute error (second y-y) : [5.19554857e-09 3.52122796e-08 1.19578457e-08 1.53652815e-09
4.80837005e-08 3.36570827e-09 4.30748738e-08 3.52404705e-08
3.27628785e-09]
Explanation: Verification that all derivatives are correctly interpolated at training points.
—
Step 8: Generate test predictions#
x1_test = np.linspace(0, 1, 50)
x2_test = np.linspace(0, 1, 50)
X1_test, X2_test = np.meshgrid(x1_test, x2_test)
X_test = np.column_stack([X1_test.flatten(), X2_test.flatten()])
y_test_pred = model.predict(X_test, params, calc_cov=False, return_deriv=True)
# Row 0: function, Row 1: df/dx, Row 2: df/dy, Row 3: d²f/dx², Row 4: d²f/dy²
y_func_test = y_test_pred[0, :].reshape(50, 50)
y_deriv_x_test = y_test_pred[1, :].reshape(50, 50)
y_deriv_y_test = y_test_pred[2, :].reshape(50, 50)
y_deriv_xx_test = y_test_pred[3, :].reshape(50, 50)
y_deriv_yy_test = y_test_pred[4, :].reshape(50, 50)
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[2, 1]], [[1, 2]], [[2, 2]]]
Explanation: All predictions (function and derivatives) are computed and reshaped for visualization.
—
Step 9: Visualize absolute errors#
import matplotlib.pyplot as plt
# Compute absolute errors
abs_error_func = np.abs(y_func_test - (np.sin(X1_test) * np.cos(X2_test)))
abs_error_dx = np.abs(y_deriv_x_test - (np.cos(X1_test) * np.cos(X2_test)))
abs_error_dy = np.abs(y_deriv_y_test - (-np.sin(X1_test) * np.sin(X2_test)))
abs_error_xx = np.abs(y_deriv_xx_test - (-np.sin(X1_test) * np.cos(X2_test)))
abs_error_yy = np.abs(y_deriv_yy_test - (-np.sin(X1_test) * np.cos(X2_test)))
# Setup figure
fig, axs = plt.subplots(1, 5, figsize=(24, 5))
# Titles and errors
titles = [
r'Absolute Error: $f(x,y)$',
r'Absolute Error: $\partial f / \partial x$',
r'Absolute Error: $\partial f / \partial y$',
r'Absolute Error: $\partial^2 f / \partial x^2$',
r'Absolute Error: $\partial^2 f / \partial y^2$'
]
errors = [abs_error_func, abs_error_dx, abs_error_dy, abs_error_xx, abs_error_yy]
cmaps = ['Reds', 'Greens', 'Blues', 'Greens', 'Blues']
# Plot all
for ax, err, title, cmap in zip(axs, errors, titles, cmaps):
cs = ax.contourf(X1_test, X2_test, err, levels=50, cmap=cmap)
ax.scatter(X_train[:,0], X_train[:,1], c='k', s=40)
ax.set_title(title, fontsize=12)
ax.set_xlabel('x')
ax.set_ylabel('y')
fig.colorbar(cs, ax=ax)
plt.tight_layout()
plt.show()
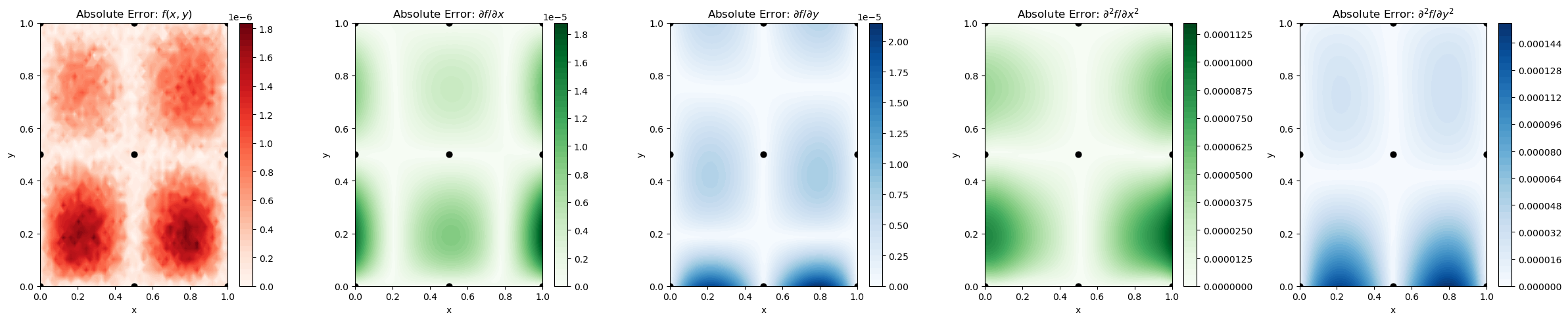
Explanation: Including second-order derivatives helps DEGP capture curvature and local convexity/concavity information, enhancing interpolation and extrapolation accuracy near sparse training regions.
—
Summary#
This example demonstrates 2D second-order DEGP. By incorporating both first and second-order partial derivatives:
The GP captures local curvature in multiple dimensions
Predictions account for surface bending and convexity
Accuracy is significantly improved in regions with high curvature
The model provides reliable derivative predictions across the domain
Key Benefits of Higher-Order Derivatives:
More accurate interpolation between sparse training points
Better extrapolation behavior
Improved gradient predictions for optimization applications
Reduced uncertainty in high-curvature regions
—
Example 5: 1D Heterogeneous Derivative Coverage#
Overview#
This example demonstrates how to use different derivative orders at different training points using the derivative_locations parameter. This is useful when:
Higher-order derivatives are expensive to compute and should only be used where needed
Derivative information is only available at certain locations (e.g., from sensors or simulations)
You want to concentrate derivative information in regions of high curvature or importance
We learn \(f(x) = \sin(2x) + 0.5\cos(5x)\) with:
All points: Function values
All points: First-order derivatives
Interior points only: Second-order derivatives (curvature information where it matters most)
—
Step 1: Import required packages#
import numpy as np
from jetgp.full_degp.degp import degp
import matplotlib.pyplot as plt
print("Modules imported successfully.")
Modules imported successfully.
—
Step 2: Define training data with heterogeneous derivative coverage#
# Define training points
X_train = np.linspace(0, 2, 7).reshape(-1, 1)
n_train = len(X_train)
# Identify boundary and interior points
boundary_indices = [0, n_train - 1] # First and last points
interior_indices = list(range(1, n_train - 1)) # Middle points
all_indices = list(range(n_train))
print(f"Total training points: {n_train}")
print(f"Boundary indices: {boundary_indices}")
print(f"Interior indices: {interior_indices}")
# Define the true function and its derivatives
def f(x):
return np.sin(2*x) + 0.5*np.cos(5*x)
def df(x):
return 2*np.cos(2*x) - 2.5*np.sin(5*x)
def d2f(x):
return -4*np.sin(2*x) - 12.5*np.cos(5*x)
# Compute training data
y_func = f(X_train)
y_deriv1 = df(X_train)
y_deriv2_interior = d2f(X_train[interior_indices]) # Only at interior points!
# Build y_train list
# Note: y_deriv2 only has len(interior_indices) entries, not n_train
y_train = [y_func, y_deriv1, y_deriv2_interior]
print(f"\nTraining data shapes:")
print(f" Function values: {y_func.shape} (all {n_train} points)")
print(f" 1st derivatives: {y_deriv1.shape} (all {n_train} points)")
print(f" 2nd derivatives: {y_deriv2_interior.shape} (only {len(interior_indices)} interior points)")
Total training points: 7
Boundary indices: [0, 6]
Interior indices: [1, 2, 3, 4, 5]
Training data shapes:
Function values: (7, 1) (all 7 points)
1st derivatives: (7, 1) (all 7 points)
2nd derivatives: (5, 1) (only 5 interior points)
Explanation:
The key insight here is that y_deriv2_interior has fewer entries than y_func and y_deriv1.
The second derivative is only computed at interior points where curvature information is most valuable.
—
Step 3: Define derivative indices and locations#
# Derivative specification: 1st and 2nd order derivatives
der_indices = [[[[1, 1]], [[1, 2]]]]
# Derivative locations: specify which points have each derivative
derivative_locations = [
all_indices, # 1st derivative (df/dx) at ALL points
interior_indices # 2nd derivative (d²f/dx²) at INTERIOR points only
]
print("der_indices:", der_indices)
print("derivative_locations:", derivative_locations)
der_indices: [[[[1, 1]], [[1, 2]]]]
derivative_locations: [[0, 1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5]]
Explanation:
The derivative_locations list has one entry per derivative in der_indices:
First entry: indices where first derivative is available (all 7 points)
Second entry: indices where second derivative is available (5 interior points)
This structure must match the y_train list exactly.
—
Step 4: Initialize DEGP model with derivative_locations#
model = degp(
X_train,
y_train,
n_order=2,
n_bases=1,
der_indices=der_indices,
derivative_locations=derivative_locations, # Key parameter!
normalize=True,
kernel="SE",
kernel_type="anisotropic"
)
print("DEGP model with heterogeneous derivative coverage initialized.")
DEGP model with heterogeneous derivative coverage initialized.
Explanation:
The derivative_locations parameter tells DEGP exactly which training points have each type of derivative information.
—
Step 5: Optimize hyperparameters#
params = model.optimize_hyperparameters(
optimizer='pso',
pop_size=100,
n_generations=15,
local_opt_every=15,
debug=False
)
print("Optimized hyperparameters:", params)
Stopping: maximum iterations reached --> 15
Optimized hyperparameters: [ 8.95780680e-03 4.19292282e-01 -1.51087304e+01]
—
Step 6: Validate predictions at training points#
# Predict with return_deriv=True to get derivative predictions
y_train_pred = model.predict(X_train, params, calc_cov=False, return_deriv=True)
# Output shape is [n_derivatives + 1, n_points]
# Row 0: function (n_train points)
# Row 1: 1st derivative (n_train points)
# Row 2: 2nd derivative (len(interior_indices) points)
y_func_pred = y_train_pred[0, :]
y_deriv1_pred = y_train_pred[1, :]
y_deriv2_pred = y_train_pred[2, interior_indices]
# Compute errors
abs_error_func = np.abs(y_func_pred.flatten() - y_func.flatten())
abs_error_d1 = np.abs(y_deriv1_pred.flatten() - y_deriv1.flatten())
abs_error_d2 = np.abs(y_deriv2_pred.flatten() - y_deriv2_interior.flatten())
print("Absolute error (function) at all training points:")
print(f" {abs_error_func}")
print("\nAbsolute error (1st derivative) at all training points:")
print(f" {abs_error_d1}")
print("\nAbsolute error (2nd derivative) at interior points only:")
print(f" {abs_error_d2}")
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[1, 2]]]
Warning: Cholesky decomposition failed via scipy, using standard np solve instead.
Absolute error (function) at all training points:
[1.95660397e-08 1.61217033e-08 4.54024768e-09 2.04040038e-08
7.53119611e-09 4.87798624e-09 1.11146570e-08]
Absolute error (1st derivative) at all training points:
[1.08431806e-08 1.56174633e-08 2.02459838e-09 2.55145156e-08
2.18248579e-08 1.76762427e-09 5.84725892e-09]
Absolute error (2nd derivative) at interior points only:
[1.85020621e-08 7.92071706e-08 4.16755093e-08 1.72419519e-08
1.22257351e-08]
Explanation: The prediction output structure matches the training data structure:
Row 0: Function values at all points
Row 1: 1st derivatives at all points
Row 2: 2nd derivatives only at interior points (matching
derivative_locations)
—
Step 7: Visualize predictions and derivative coverage#
# Generate test points
X_test = np.linspace(0, 2, 200).reshape(-1, 1)
y_test_pred = model.predict(X_test, params, calc_cov=False, return_deriv=True)
n_test = len(X_test)
# Row 0: function, Row 1: 1st derivative, Row 2: 2nd derivative
y_func_test = y_test_pred[0, :]
y_d1_test = y_test_pred[1, :]
y_d2_test = y_test_pred[2, :]
# True values for comparison
y_true = f(X_test)
dy_true = df(X_test)
d2y_true = d2f(X_test)
# Create figure
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# --- Plot 1: Function ---
ax1 = axes[0, 0]
ax1.plot(X_test, y_true, 'b-', linewidth=2, label='True f(x)')
ax1.plot(X_test, y_func_test, 'r--', linewidth=2, label='GP prediction')
ax1.scatter(X_train[boundary_indices].flatten(), y_func[boundary_indices].flatten(),
c='orange', s=150, marker='s', zorder=5, edgecolors='black',
label='Boundary (f, df only)')
ax1.scatter(X_train[interior_indices].flatten(), y_func[interior_indices].flatten(),
c='green', s=150, marker='o', zorder=5, edgecolors='black',
label='Interior (f, df, d²f)')
ax1.set_xlabel('x', fontsize=12)
ax1.set_ylabel('f(x)', fontsize=12)
ax1.set_title('Function Prediction', fontsize=14)
ax1.legend(loc='best')
ax1.grid(True, alpha=0.3)
# --- Plot 2: First Derivative ---
ax2 = axes[0, 1]
ax2.plot(X_test, dy_true, 'b-', linewidth=2, label="True f'(x)")
ax2.plot(X_test, y_d1_test, 'r--', linewidth=2, label='GP prediction')
ax2.scatter(X_train[boundary_indices].flatten(), y_deriv1[boundary_indices].flatten(),
c='orange', s=150, marker='s', zorder=5, edgecolors='black')
ax2.scatter(X_train[interior_indices].flatten(), y_deriv1[interior_indices].flatten(),
c='green', s=150, marker='o', zorder=5, edgecolors='black')
ax2.set_xlabel('x', fontsize=12)
ax2.set_ylabel("f'(x)", fontsize=12)
ax2.set_title('First Derivative Prediction', fontsize=14)
ax2.legend(loc='best')
ax2.grid(True, alpha=0.3)
# --- Plot 3: Second Derivative ---
ax3 = axes[1, 0]
ax3.plot(X_test, d2y_true, 'b-', linewidth=2, label="True f''(x)")
ax3.plot(X_test, y_d2_test, 'r--', linewidth=2, label='GP prediction')
# Only interior points have 2nd derivative training data
ax3.scatter(X_train[interior_indices].flatten(), d2f(X_train[interior_indices]).flatten(),
c='green', s=150, marker='o', zorder=5, edgecolors='black',
label='Interior (has d²f)')
# Mark boundary points without 2nd derivative
ax3.axvline(x=X_train[0, 0], color='orange', linestyle=':', alpha=0.7)
ax3.axvline(x=X_train[-1, 0], color='orange', linestyle=':', alpha=0.7,
label='Boundary (no d²f)')
ax3.set_xlabel('x', fontsize=12)
ax3.set_ylabel("f''(x)", fontsize=12)
ax3.set_title('Second Derivative Prediction', fontsize=14)
ax3.legend(loc='best')
ax3.grid(True, alpha=0.3)
# --- Plot 4: Derivative Coverage Visualization ---
ax4 = axes[1, 1]
ax4.axis('off')
coverage_text = """
Derivative Coverage Summary
===========================
Training Points: 7 total
Point Type | f(x) | df/dx | d²f/dx²
--------------|------|-------|--------
Boundary (2) | ✓ | ✓ | ✗
Interior (5) | ✓ | ✓ | ✓
derivative_locations structure:
der_indices = [[[[1, 1]], [[1, 2]]]]
derivative_locations = [
[0, 1, 2, 3, 4, 5, 6], # df/dx at all
[1, 2, 3, 4, 5] # d²f/dx² interior only
]
Benefits:
• Reduced computational cost (fewer 2nd derivatives)
• Curvature info concentrated where needed
• Boundary regions rely on function + slope only
"""
ax4.text(0.05, 0.95, coverage_text, transform=ax4.transAxes,
fontsize=11, verticalalignment='top', fontfamily='monospace',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
plt.tight_layout()
plt.show()
Note: derivs_to_predict is None. Predictions will include all derivatives used in training: [[[1, 1]], [[1, 2]]]
Warning: Cholesky decomposition failed via scipy, using standard np solve instead.
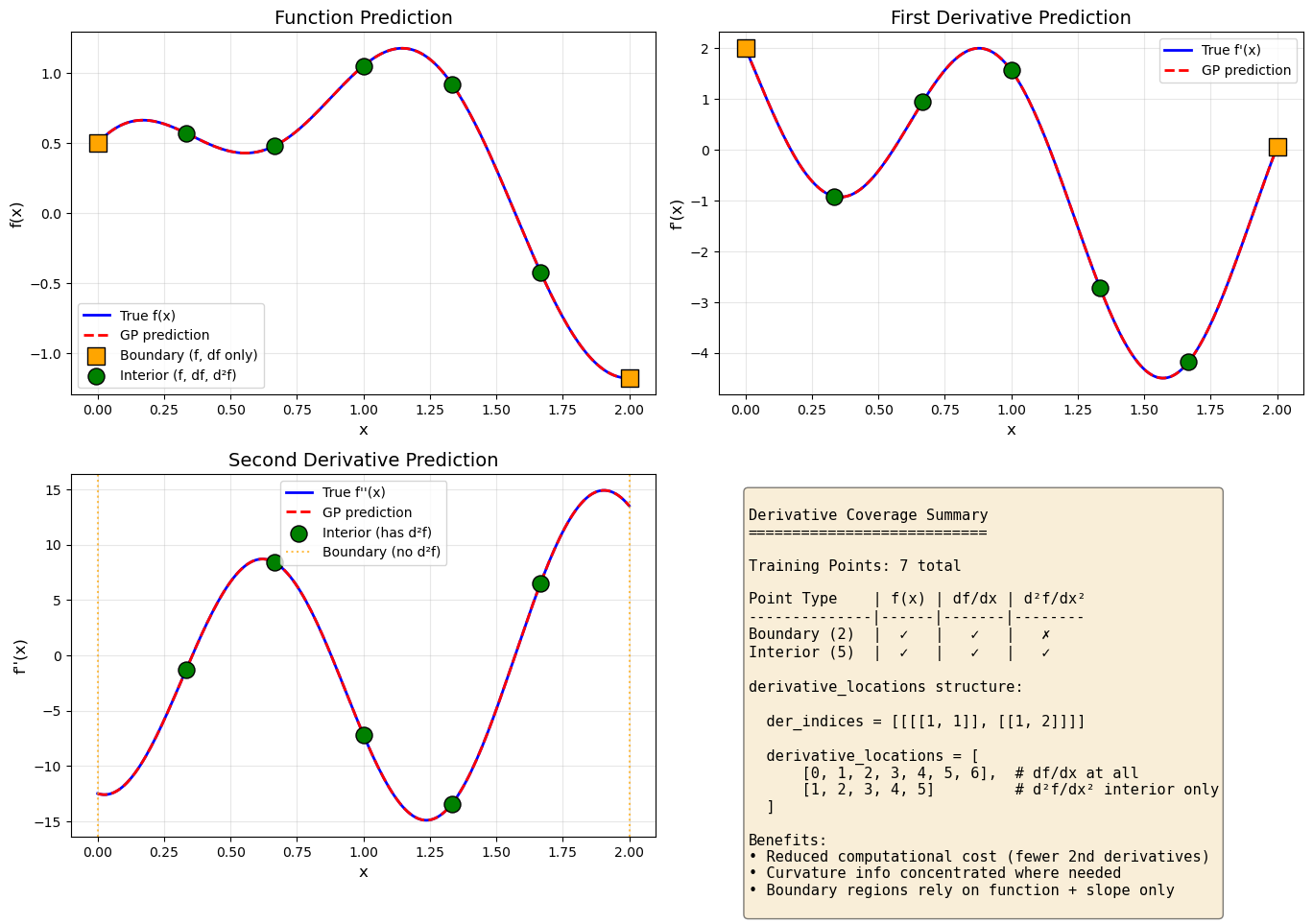
Explanation: The visualization shows:
Orange squares: Boundary points with only function values and first derivatives
Green circles: Interior points with full derivative coverage (1st and 2nd order)
The GP successfully interpolates all training data and provides smooth predictions
—
Step 8: Compare errors at boundary vs interior#
# Evaluate prediction accuracy in different regions
boundary_test_mask = (X_test.flatten() < 0.3) | (X_test.flatten() > 1.7)
interior_test_mask = ~boundary_test_mask
func_error_boundary = np.mean(np.abs(y_func_test[boundary_test_mask].flatten() -
y_true[boundary_test_mask].flatten()))
func_error_interior = np.mean(np.abs(y_func_test[interior_test_mask].flatten() -
y_true[interior_test_mask].flatten()))
d2_error_boundary = np.mean(np.abs(y_d2_test[boundary_test_mask].flatten() -
d2y_true[boundary_test_mask].flatten()))
d2_error_interior = np.mean(np.abs(y_d2_test[interior_test_mask].flatten() -
d2y_true[interior_test_mask].flatten()))
print("Mean Absolute Error Comparison:")
print(f"\nFunction prediction:")
print(f" Boundary region: {func_error_boundary:.6f}")
print(f" Interior region: {func_error_interior:.6f}")
print(f"\nSecond derivative prediction:")
print(f" Boundary region: {d2_error_boundary:.6f}")
print(f" Interior region: {d2_error_interior:.6f}")
Mean Absolute Error Comparison:
Function prediction:
Boundary region: 0.000000
Interior region: 0.000000
Second derivative prediction:
Boundary region: 0.000013
Interior region: 0.000000
Explanation: This comparison shows that even without second-order derivative information at the boundaries, the GP can still make reasonable predictions by leveraging the curvature information from nearby interior points.
—
Summary#
This example demonstrates heterogeneous derivative coverage in DEGP using derivative_locations. Key takeaways:
Flexible derivative specification: Different training points can have different derivative orders
Matching structure:
y_train,der_indices, andderivative_locationsmust be consistentCost reduction: Compute expensive higher-order derivatives only where they provide the most value
Practical applications: - Sensor data with varying derivative availability - Concentrated derivative information in regions of interest - Balancing accuracy vs computational cost
When to use heterogeneous derivative coverage:
Higher-order derivatives are expensive to compute
Derivative data comes from multiple sources with different capabilities
You want to focus derivative information in high-curvature or high-importance regions
Boundary conditions provide limited derivative information
—
Example 6: Predicting Untrained Partial Derivatives#
Overview#
This example demonstrates that DEGP can predict partial derivatives that were not observed during training. The cross-covariance \(K_*\) is constructed directly from kernel derivatives, so any partial derivative within the n_bases-dimensional OTI space can be predicted regardless of whether training data was provided for it.
We learn \(f(x_1, x_2) = \sin(x_1) + x_2^2\) using function values and the first partial derivative with respect to \(x_1\) only. At prediction time we also request \(\partial f / \partial x_2\), which was never observed.
—
Step 1: Import required packages#
import numpy as np
from jetgp.full_degp.degp import degp
import matplotlib.pyplot as plt
print("Modules imported successfully.")
Modules imported successfully.
—
Step 2: Define the function and training data#
np.random.seed(42)
# 2D input — 6×6 training grid
x_vals = np.linspace(0, 1, 7)
X_train = np.array([[x1, x2] for x1 in x_vals for x2 in x_vals])
def f(X): return np.sin(X[:, 0]) + X[:, 1] ** 2
def df_dx1(X): return np.cos(X[:, 0])
def df_dx2(X): return 2.0 * X[:, 1] # NOT included in training
y_func = f(X_train).reshape(-1, 1)
y_dx1 = df_dx1(X_train).reshape(-1, 1)
y_train = [y_func, y_dx1] # df/dx2 deliberately omitted
print(f"Training points : {X_train.shape[0]}")
print(f"Training outputs: f, df/dx1 (df/dx2 NOT provided)")
Training points : 49
Training outputs: f, df/dx1 (df/dx2 NOT provided)
Explanation: A 6×6 grid of 2D points is used. The training list contains function values and only the first partial derivative; \(\partial f / \partial x_2\) is intentionally left out.
—
Step 3: Define derivative indices and locations#
# Only dx1 is in the training set
der_indices = [[[[1, 1]]]]
n_train = len(X_train)
derivative_locations = [
list(range(n_train)), # df/dx1 at all points
]
print("der_indices :", der_indices)
print("derivative_locations : 1 entry covering all", n_train, "points")
der_indices : [[[[1, 1]]]]
derivative_locations : 1 entry covering all 49 points
Explanation:
der_indices lists only \(\partial f/\partial x_1\). The second coordinate axis is absent from training — but it exists in the OTI space because n_bases=2 spans both coordinate axes.
—
Step 4: Initialize the DEGP model#
# n_bases=2 because the input space is 2-dimensional.
# This means the OTI module includes basis units e1, e2
# for both coordinate directions, even though dx2 is not trained.
model = degp(
X_train, y_train,
n_order=1, n_bases=2,
der_indices=der_indices,
derivative_locations=derivative_locations,
normalize=True,
kernel="SE", kernel_type="anisotropic"
)
print("DEGP model (2D, training f+dx1 only) initialized.")
DEGP model (2D, training f+dx1 only) initialized.
—
Step 5: Optimize hyperparameters#
params = model.optimize_hyperparameters(
optimizer='powell',
n_restart_optimizer=5,
debug=False
)
print("Optimized hyperparameters:", params)
Optimized hyperparameters: [-1.10174431 -0.61477023 1.55130939 -5.79999067]
—
Step 6: Predict the untrained derivative#
np.random.seed(7)
X_test = np.random.uniform(0, 1, (50, 2))
# Request df/dx2 via derivs_to_predict — it was NOT in the training set
pred = model.predict(
X_test, params,
calc_cov=False,
return_deriv=True,
derivs_to_predict=[[[2, 1]]] # dx2 only
)
# pred shape: (2, n_test) — row 0 = f, row 1 = df/dx2
f_pred = pred[0, :]
dx2_pred = pred[1, :]
dx2_true = df_dx2(X_test).flatten()
f_true = f(X_test).flatten()
rmse_f = float(np.sqrt(np.mean((f_pred - f_true) ** 2)))
rmse_dx2 = float(np.sqrt(np.mean((dx2_pred - dx2_true) ** 2)))
corr_dx2 = float(np.corrcoef(dx2_pred, dx2_true)[0, 1])
print(f"Function RMSE : {rmse_f:.4e}")
print(f"df/dx2 RMSE (untrained) : {rmse_dx2:.4e}")
print(f"df/dx2 correlation : {corr_dx2:.4f}")
Function RMSE : 1.1830e-06
df/dx2 RMSE (untrained) : 9.2540e-06
df/dx2 correlation : 1.0000
Explanation:
derivs_to_predict=[[[2, 1]]] requests the first partial derivative along the second coordinate axis. Because n_bases=2, basis element e2 already exists in the OTI space — the model simply reads the corresponding Taylor coefficient from \(\phi_\text{exp}\) without needing any observed training data for that direction.
—
Step 7: Visualise the untrained derivative prediction#
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Scatter: predicted vs true df/dx2
axes[0].scatter(dx2_true, dx2_pred, alpha=0.7, edgecolors='k', linewidths=0.5)
lims = [min(dx2_true.min(), dx2_pred.min()) - 0.1,
max(dx2_true.max(), dx2_pred.max()) + 0.1]
axes[0].plot(lims, lims, 'r--', linewidth=2, label='Perfect prediction')
axes[0].set_xlabel(r'True $\partial f / \partial x_2$')
axes[0].set_ylabel(r'Predicted $\partial f / \partial x_2$')
axes[0].set_title(f'Untrained df/dx2 (r = {corr_dx2:.3f})')
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# Sort by x2 for a clean line plot
sort_idx = np.argsort(X_test[:, 1])
axes[1].plot(X_test[sort_idx, 1], dx2_true[sort_idx],
'b-', linewidth=2, label=r'True $2x_2$')
axes[1].plot(X_test[sort_idx, 1], dx2_pred[sort_idx],
'r--', linewidth=2, label='GP prediction')
axes[1].set_xlabel(r'$x_2$')
axes[1].set_ylabel(r'$\partial f / \partial x_2$')
axes[1].set_title('Predicted vs True along x2 axis')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
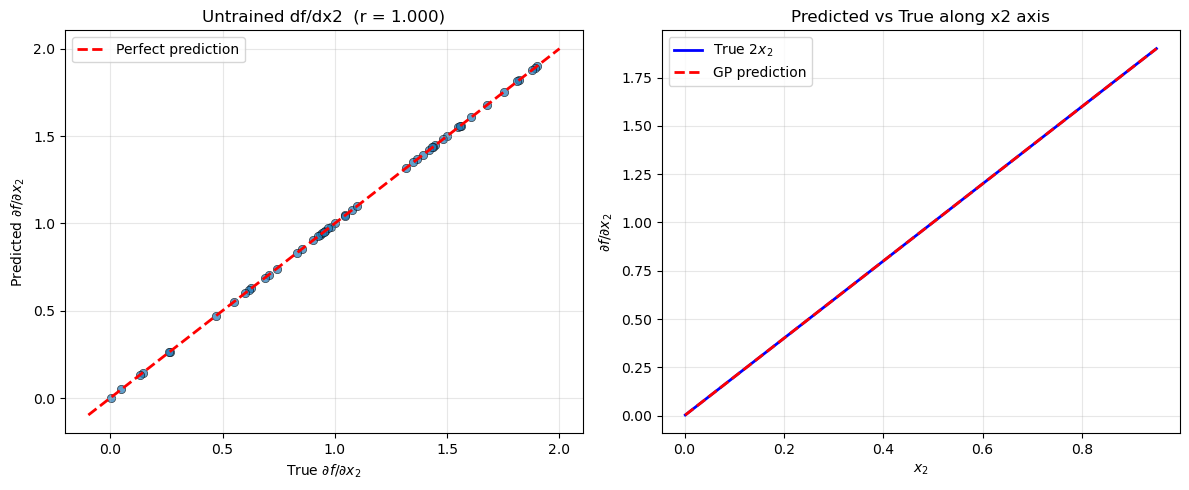
Explanation: The scatter plot (left) and line plot (right) both show that the GP successfully recovers \(\partial f/\partial x_2 = 2x_2\) even though no training data for this derivative was provided. The information propagates through the kernel structure: the GP has learned the length scale along \(x_2\) from the function values, and the kernel’s analytic derivative with respect to \(e_2\) supplies the required cross-covariance.
—
Summary#
This example demonstrates predicting untrained partial derivatives in DEGP.
Key takeaways:
No extra setup required: simply pass
derivs_to_predictat prediction time with any index withinn_basesWorks because ``n_bases`` spans all coordinate axes: setting
n_bases=2for a 2D problem ensures \(e_1, e_2\) both exist in the OTI space, regardless of which derivatives appear in trainingCross-covariance from kernel derivatives: \(K_*\) is built analytically from the kernel, not from observed data, so untrained directions are always accessible
Accuracy depends on function structure: the prediction quality for the untrained derivative reflects how well the GP has learned the underlying function
When this feature is useful:
Derivative data is expensive and only a subset of directions can be observed during training
Post-hoc sensitivity analysis in directions not originally anticipated
Exploring gradient information along new axes without retraining
—
Example 7: 2D Function-Only Training with Derivative Predictions#
Overview#
This example demonstrates that DEGP can be trained on function values only in a 2D input space and still predict both partial derivatives with uncertainty at test points. No derivative observations are required during training; the cross-covariance \(K_*\) between \(f\) and its partial derivatives is derived analytically from the kernel.
True function: \(f(x_1,x_2) = \sin(x_1)\cos(x_2)\)
True partials: \(\partial f/\partial x_1 = \cos(x_1)\cos(x_2)\), \(\quad\partial f/\partial x_2 = -\sin(x_1)\sin(x_2)\)
—
Step 1: Import required packages#
import warnings
import numpy as np
import matplotlib.pyplot as plt
from jetgp.full_degp.degp import degp
print("Modules imported successfully.")
Modules imported successfully.
—
Step 2: Define the true function and build training data#
def f(X):
return np.sin(X[:, 0]) * np.cos(X[:, 1])
def df_dx1(X):
return np.cos(X[:, 0]) * np.cos(X[:, 1])
def df_dx2(X):
return -np.sin(X[:, 0]) * np.sin(X[:, 1])
# 5×5 training grid — function values ONLY
x1_tr = np.linspace(0, 2 * np.pi, 6)
x2_tr = np.linspace(0, 2 * np.pi, 6)
G1, G2 = np.meshgrid(x1_tr, x2_tr)
X_train = np.column_stack([G1.ravel(), G2.ravel()]) # shape (36, 2)
y_func = f(X_train).reshape(-1, 1)
y_train = [y_func] # no derivative arrays
print(f"X_train shape : {X_train.shape}")
print(f"y_train[0] shape : {y_train[0].shape}")
X_train shape : (36, 2)
y_train[0] shape : (36, 1)
Explanation:
A sparse 5×5 grid provides 25 training locations. y_train contains only function values;
no derivative arrays are included. Setting der_indices=[] at construction tells DEGP that
the training covariance is built from function values alone.
—
Step 3: Initialise DEGP model for function-only training#
with warnings.catch_warnings():
warnings.simplefilter("ignore") # suppress "0 derivatives" notice
model = degp(
X_train, y_train,
n_order=1, n_bases=2,
der_indices=[],
normalize=True,
kernel="SE", kernel_type="anisotropic",
)
print("DEGP model (function-only, 2D) initialised.")
DEGP model (function-only, 2D) initialised.
Explanation:
n_order=1: enables first-order OTI arithmetic, required to form the kernel cross-derivativesn_bases=2: one OTI pair per input dimension (x1, x2)der_indices=[]: no derivative observations — training kernel is built from function values only
—
Step 4: Optimise hyperparameters#
params = model.optimize_hyperparameters(
optimizer='pso',
pop_size=100,
n_generations=15,
local_opt_every=15,
debug=False,
)
print("Optimised hyperparameters:", params)
Stopping: maximum iterations reached --> 15
Optimised hyperparameters: [-1.39083569e-02 4.47278616e-02 4.47652758e-01 -1.51974132e+01]
—
Step 5: Predict f, df/dx1, and df/dx2 with uncertainty#
n_test = 20
x1_te = np.linspace(0, 2 * np.pi, n_test)
x2_te = np.linspace(0, 2 * np.pi, n_test)
G1t, G2t = np.meshgrid(x1_te, x2_te)
X_test = np.column_stack([G1t.ravel(), G2t.ravel()])
# derivs_to_predict: [[1,1]] → df/dx1 (1st-order w.r.t. basis 1)
# [[2,1]] → df/dx2 (1st-order w.r.t. basis 2)
mean, var = model.predict(
X_test, params,
calc_cov=True,
return_deriv=True,
derivs_to_predict=[[[1, 1]], [[2, 1]]],
)
# mean shape: (3, n_test²) — rows: [f, df/dx1, df/dx2]
shape2d = (n_test, n_test)
f_mean_grid = mean[0, :].reshape(shape2d)
dx1_mean_grid = mean[1, :].reshape(shape2d)
dx2_mean_grid = mean[2, :].reshape(shape2d)
f_true_grid = f(X_test).reshape(shape2d)
dx1_true_grid = df_dx1(X_test).reshape(shape2d)
dx2_true_grid = df_dx2(X_test).reshape(shape2d)
print(f"Prediction output shape: {mean.shape}")
Prediction output shape: (3, 400)
Explanation:
derivs_to_predict=[[[1,1]], [[2,1]]] requests the first-order partial derivative with
respect to each input dimension. Both derivatives were never observed during training; they
are recovered through the kernel’s analytic cross-covariance.
—
Step 6: Accuracy metrics#
f_rmse = float(np.sqrt(np.mean((mean[0, :] - f(X_test)) ** 2)))
dx1_rmse = float(np.sqrt(np.mean((mean[1, :] - df_dx1(X_test)) ** 2)))
dx2_rmse = float(np.sqrt(np.mean((mean[2, :] - df_dx2(X_test)) ** 2)))
dx1_corr = float(np.corrcoef(mean[1, :], df_dx1(X_test))[0, 1])
dx2_corr = float(np.corrcoef(mean[2, :], df_dx2(X_test))[0, 1])
print(f"f RMSE : {f_rmse:.4e}")
print(f"df/dx1 RMSE : {dx1_rmse:.4e} Pearson r: {dx1_corr:.3f}")
print(f"df/dx2 RMSE : {dx2_rmse:.4e} Pearson r: {dx2_corr:.3f}")
f RMSE : 8.8283e-03
df/dx1 RMSE : 9.9000e-03 Pearson r: 1.000
df/dx2 RMSE : 3.1993e-02 Pearson r: 0.998
—
Step 7: Visualise predictions#
extent = [0, 2 * np.pi, 0, 2 * np.pi]
titles_row = [r"$f(x_1,x_2)$",
r"$\partial f/\partial x_1$",
r"$\partial f/\partial x_2$"]
trues = [f_true_grid, dx1_true_grid, dx2_true_grid]
means = [f_mean_grid, dx1_mean_grid, dx2_mean_grid]
stds = [np.sqrt(np.abs(var[r, :])).reshape(shape2d) for r in range(3)]
fig, axes = plt.subplots(3, 3, figsize=(14, 12))
kw = dict(origin="lower", extent=extent, aspect="auto")
for row, (label, true, gp_mean, gp_std) in enumerate(
zip(titles_row, trues, means, stds)):
vmin, vmax = true.min(), true.max()
im0 = axes[row, 0].imshow(true, **kw, vmin=vmin, vmax=vmax, cmap="RdBu_r")
axes[row, 0].set_title(f"True {label}")
plt.colorbar(im0, ax=axes[row, 0])
im1 = axes[row, 1].imshow(gp_mean, **kw, vmin=vmin, vmax=vmax, cmap="RdBu_r")
axes[row, 1].set_title(f"GP mean {label}")
plt.colorbar(im1, ax=axes[row, 1])
im2 = axes[row, 2].imshow(gp_std, **kw, cmap="viridis")
axes[row, 2].set_title(f"GP std {label}")
plt.colorbar(im2, ax=axes[row, 2])
for col in range(3):
axes[row, col].set_xlabel("$x_1$")
axes[row, col].set_ylabel("$x_2$")
for col in range(2):
axes[0, col].scatter(X_train[:, 0], X_train[:, 1],
c="k", s=20, zorder=5, label="Training pts")
axes[0, 0].legend(fontsize=8, loc="upper right")
plt.suptitle(
"DEGP 2D — function-only training, derivative predictions\n"
r"$f(x_1,x_2) = \sin(x_1)\cos(x_2)$",
fontsize=13,
)
plt.tight_layout()
plt.show()
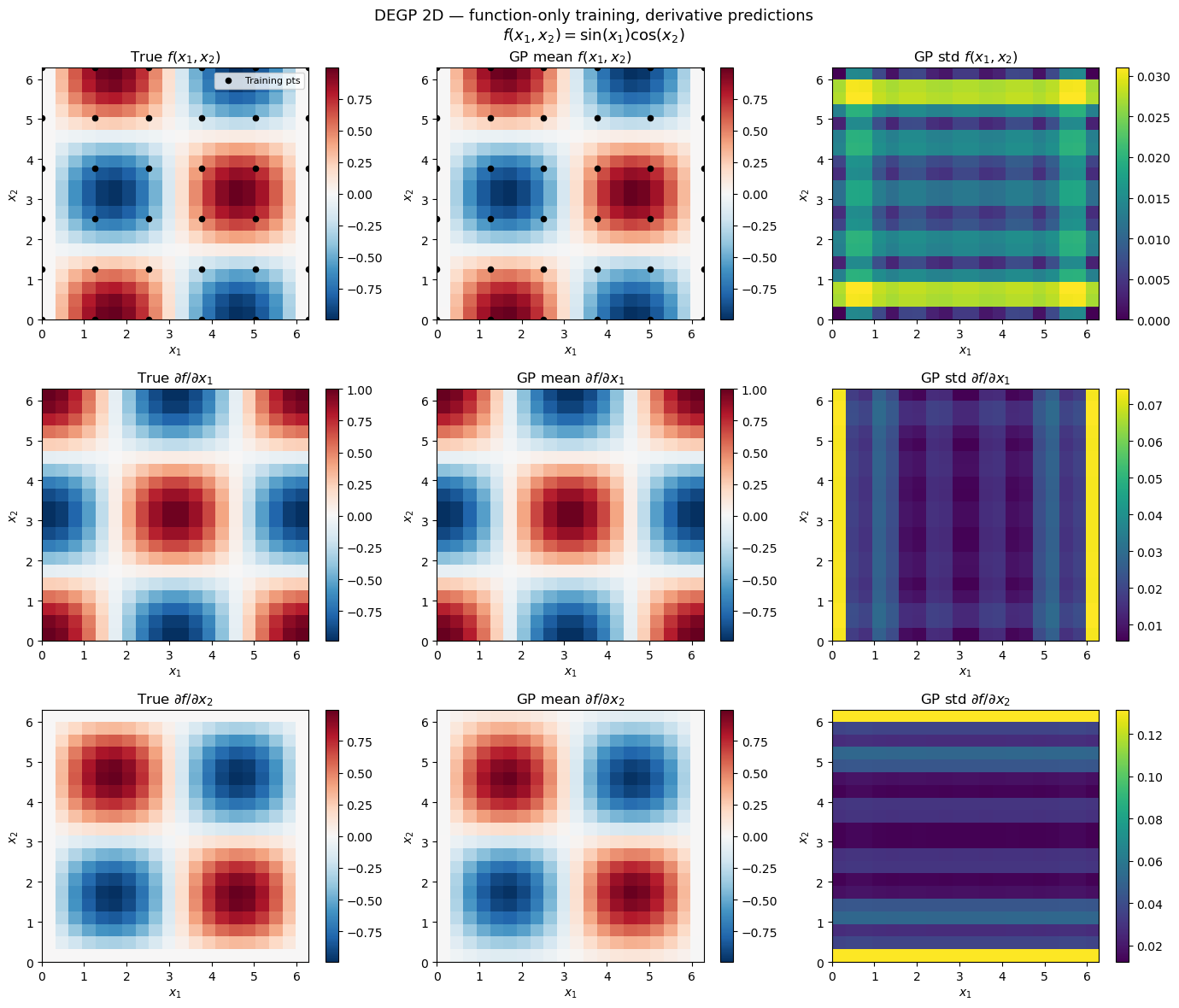
Explanation: The 3×3 grid shows true values, GP posterior means, and posterior standard deviations for \(f\), \(\partial f/\partial x_1\), and \(\partial f/\partial x_2\). Despite training exclusively on function values, DEGP recovers the gradient structure through the kernel’s analytic cross-covariance.
—
Summary#
This example demonstrates 2D function-only DEGP with untrained derivative predictions.
Key takeaways:
Zero derivative observations required:
der_indices=[]excludes all derivative data from training; partial derivatives remain predictable viaderivs_to_predictat test time``n_bases`` spans all coordinate axes automatically: for a 2D problem,
n_bases=2ensures \(e_1, e_2\) both exist in the OTI spaceUncertainty is meaningful: the GP standard deviation captures where derivative predictions carry most uncertainty (sparse training regions)
Same API as untrained single-direction prediction (Example 6): the only difference is that here all directions are untrained and we predict over a 2D grid